Autoencoder training on MNIST dataset ←
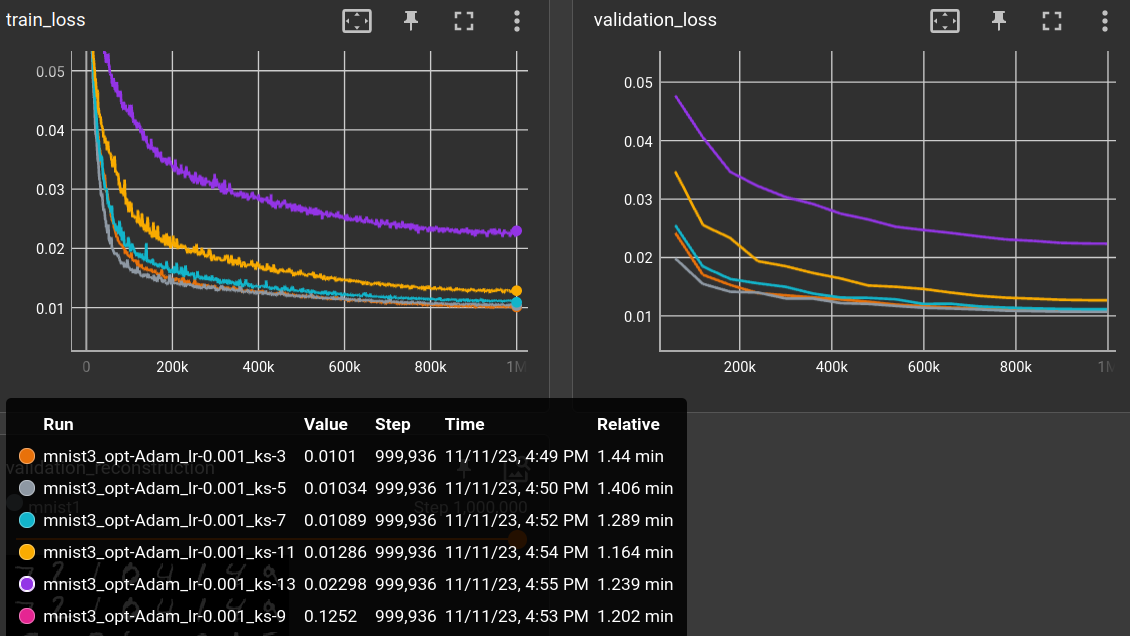
varying kernel size ←
Using a "classic" CNN autoencoder and varying the kernel size of all layers:
matrix:
opt: ["Adam"]
lr: [0.001]
ks: [3, 5, 7, 9, 11, 13]
experiment_name: mnist/mnist3_${matrix_slug}
trainer: TrainAutoencoder
globals:
SHAPE: (1, 28, 28)
CODE_SIZE: 28 * 28 // 10
train_set: |
TransformDataset(
TensorDataset(torchvision.datasets.MNIST("~/prog/data/datasets/", train=True).data),
transforms=[lambda x: x.unsqueeze(0).float() / 255.],
)
validation_set: |
TransformDataset(
TensorDataset(torchvision.datasets.MNIST("~/prog/data/datasets/", train=False).data),
transforms=[lambda x: x.unsqueeze(0).float() / 255.],
)
batch_size: 64
learnrate: ${lr}
optimizer: ${opt}
scheduler: CosineAnnealingLR
loss_function: l1
max_inputs: 1_000_000
model: |
encoder = EncoderConv2d(SHAPE, code_size=CODE_SIZE, channels=(16, 32), kernel_size=${ks})
encoded_shape = encoder.convolution.get_output_shape(SHAPE)
decoder = nn.Sequential(
nn.Linear(CODE_SIZE, math.prod(encoded_shape)),
Reshape(encoded_shape),
encoder.convolution.create_transposed(act_last_layer=False),
)
EncoderDecoder(encoder, decoder)
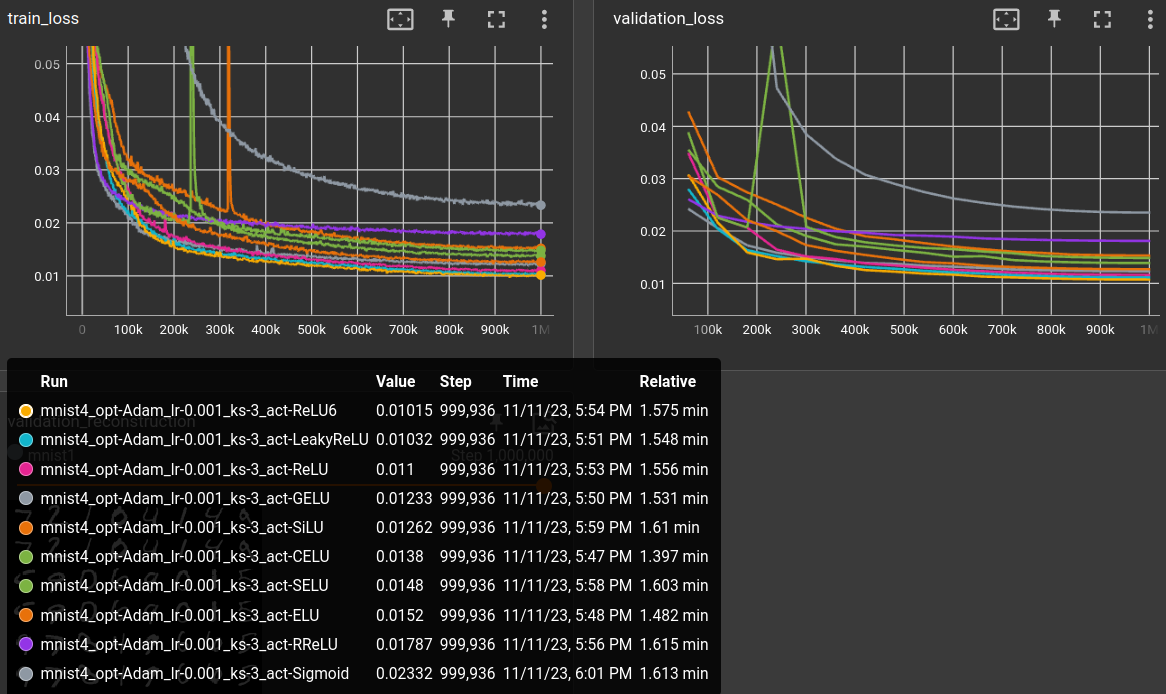
varying activation function ←
matrix:
opt: ["Adam"]
lr: [0.001]
ks: [3]
act: ["CELU", "ELU", "GELU", "LeakyReLU", "ReLU", "ReLU6", "RReLU", "SELU", "SiLU", "Sigmoid"]
experiment_name: mnist/mnist4_${matrix_slug}
trainer: TrainAutoencoder
globals:
SHAPE: (1, 28, 28)
CODE_SIZE: 28 * 28 // 10
train_set: |
TransformDataset(
TensorDataset(torchvision.datasets.MNIST("~/prog/data/datasets/", train=True).data),
transforms=[lambda x: x.unsqueeze(0).float() / 255.],
)
validation_set: |
TransformDataset(
TensorDataset(torchvision.datasets.MNIST("~/prog/data/datasets/", train=False).data),
transforms=[lambda x: x.unsqueeze(0).float() / 255.],
)
batch_size: 64
learnrate: ${lr}
optimizer: ${opt}
scheduler: CosineAnnealingLR
loss_function: l1
max_inputs: 1_000_000
model: |
encoder = EncoderConv2d(SHAPE, code_size=CODE_SIZE, channels=(16, 32), kernel_size=${ks}, act_fn=nn.${act}())
encoded_shape = encoder.convolution.get_output_shape(SHAPE)
decoder = nn.Sequential(
nn.Linear(CODE_SIZE, math.prod(encoded_shape)),
Reshape(encoded_shape),
encoder.convolution.create_transposed(act_last_layer=False),
)
EncoderDecoder(encoder, decoder)
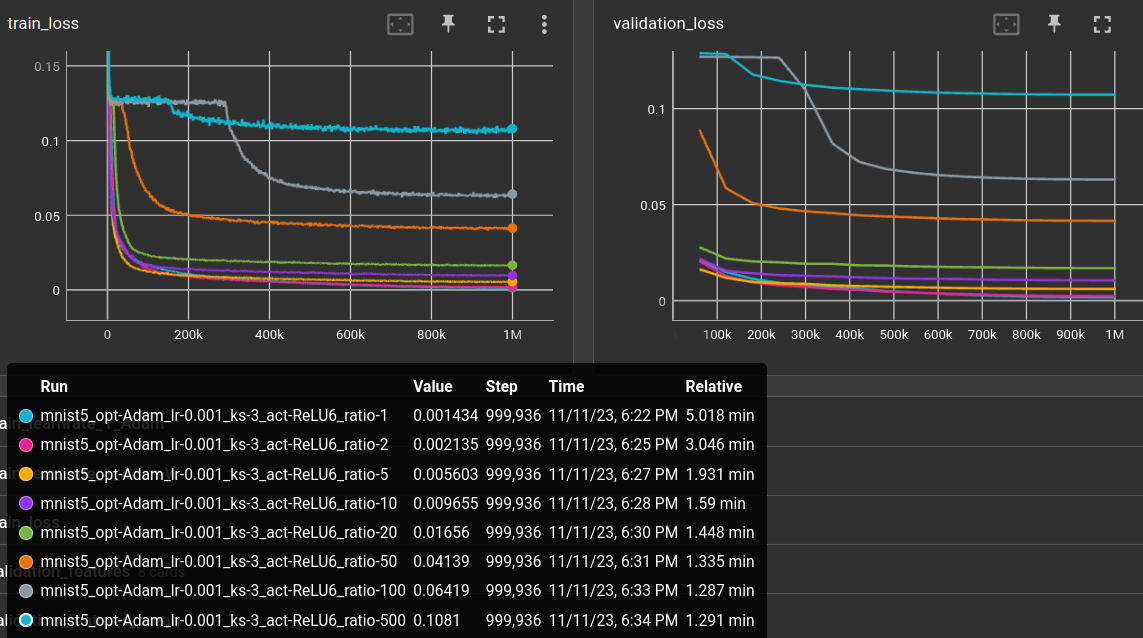
varying image to code ratio ←
ratio below defines the embedding size (1: 768, 10: 76, 500: 1)
matrix:
opt: ["Adam"]
lr: [0.001]
ks: [3]
act: ["ReLU6"]
ratio: [1, 2, 5, 10, 20, 50, 100, 500]
experiment_name: mnist/mnist5_${matrix_slug}
trainer: TrainAutoencoder
globals:
SHAPE: (1, 28, 28)
CODE_SIZE: 28 * 28 // ${ratio}
train_set: |
TransformDataset(
TensorDataset(torchvision.datasets.MNIST("~/prog/data/datasets/", train=True).data),
transforms=[lambda x: x.unsqueeze(0).float() / 255.],
)
validation_set: |
TransformDataset(
TensorDataset(torchvision.datasets.MNIST("~/prog/data/datasets/", train=False).data),
transforms=[lambda x: x.unsqueeze(0).float() / 255.],
)
batch_size: 64
learnrate: ${lr}
optimizer: ${opt}
scheduler: CosineAnnealingLR
loss_function: l1
max_inputs: 1_000_000
model: |
encoder = EncoderConv2d(SHAPE, code_size=CODE_SIZE, channels=(16, 32), kernel_size=${ks}, act_fn=nn.${act}())
encoded_shape = encoder.convolution.get_output_shape(SHAPE)
decoder = nn.Sequential(
nn.Linear(CODE_SIZE, math.prod(encoded_shape)),
Reshape(encoded_shape),
encoder.convolution.create_transposed(act_last_layer=False),
)
EncoderDecoder(encoder, decoder)
Here are the reproductions of the ratio 10, 100 and 500 runs:
| compreesion ratio: 10 | ratio: 100 | ratio: 500 |
|---|---|---|
 |
 |
 |
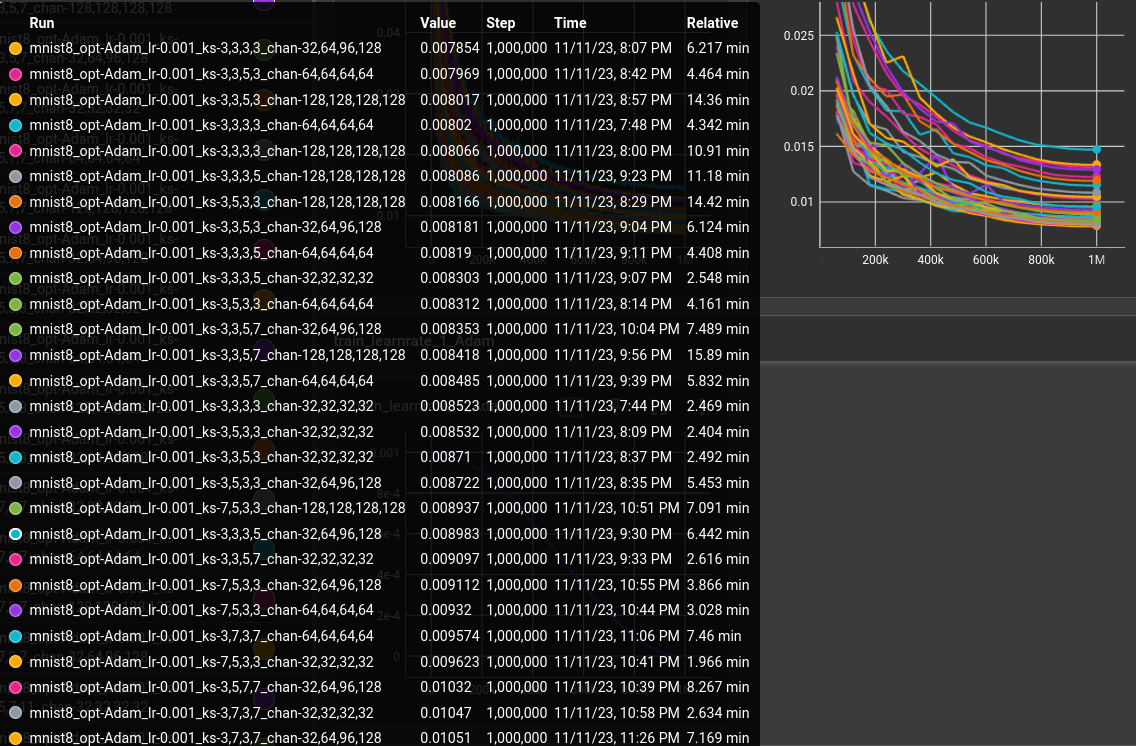
varying kernel size and number of channels ←
matrix:
opt: ["Adam"]
lr: [0.001]
ks: [
[3, 3, 3, 3], [3, 5, 3, 3], [3, 3, 5, 3], [3, 3, 3, 5],
[3, 3, 5, 7], [3, 5, 7, 7], [7, 5, 3, 3], [3, 7, 3, 7],
[3, 5, 7, 11], [11, 7, 5, 3],
]
chan: [[32, 32, 32, 32], [64, 64, 64, 64], [128, 128, 128, 128], [32, 64, 96, 128]]
$filter: len(${ks}) == len(${chan})
experiment_name: mnist/mnist8_${matrix_slug}
trainer: TrainAutoencoder
globals:
SHAPE: (1, 28, 28)
CODE_SIZE: 28 * 28 // 10
train_set: |
TransformDataset(
TensorDataset(torchvision.datasets.MNIST("~/prog/data/datasets/", train=True).data),
transforms=[lambda x: x.unsqueeze(0).float() / 255.],
)
validation_set: |
TransformDataset(
TensorDataset(torchvision.datasets.MNIST("~/prog/data/datasets/", train=False).data),
transforms=[lambda x: x.unsqueeze(0).float() / 255.],
)
batch_size: 64
learnrate: ${lr}
optimizer: ${opt}
scheduler: CosineAnnealingLR
loss_function: l1
max_inputs: 1_000_000
model: |
encoder = EncoderConv2d(SHAPE, code_size=CODE_SIZE, channels=${chan}, kernel_size=${ks}, act_fn=nn.ReLU6())
encoded_shape = encoder.convolution.get_output_shape(SHAPE)
decoder = nn.Sequential(
nn.Linear(CODE_SIZE, math.prod(encoded_shape)),
Reshape(encoded_shape),
encoder.convolution.create_transposed(act_last_layer=False),
)
EncoderDecoder(encoder, decoder)