Interest aggregation ←
This post might contain off-putting things, for two reasons: Firstly, it is investigating methods of user data aggregation, which can be an offending topic in itself and secondly, it investigates the interests of porn website users. For educational purposes only.
The data has been politely scraped over a couple of days from a free website that hosts images/videos, blogs and public user profiles. For this post i just looked at the "interests", which are zero or more words or groups of words, that each user can specify, to be found more easily on the profile search page, or to simply state the obvious.
The data published in this article does not contain any user data. Instead it is a point-cloud of interests, gathered by looking at patterns in about 116K profiles. Now dive into the realms of this little porn community with the Interest Similarity Search and read the technical details below.
Interest Similarity Search ←
Data source ←
I do not usually scrape user profiles but this data is genuinely interesting. The particular website attracts and promotes all kinds of kinkiness and perversions as long as it looks like legal content. It's a safe place for people to freely admit they require small penis humiliation, cum on food, cock milking or financial domination. And i wondered if i could produce a map of sexual interests.
Those interest strings are case-sensitive in the search page, i guess because in porn language, ANAL means something different than just anal. I lower-cased all strings but otherwise left them as they are. girl is not girls and mother/son is not the same as mother son. The site only lists the first 5 pages for any search result and then repeats, which, i think, is a fair thing to do. I got about 147K profiles at all but included only the ones with at least 5 listed interests. That's still 116K profiles which create a graph of 137K interests and 3.2M interconnections - links between one interest and another.
Graph/network representation ←
It turned out that, as graph representation, this data is quite unusable because of the overwhelming number of interconnections. The 30 most often listed interests already have like 600 connections between each other. I tried a few graph/network programs and they would stop reacting within acceptable amounts of time when loading networks with a thousand interests. Not to mention that the layouting algorithms, just by looking at interconnectedness - even weighted, do not have much chance to find a visual arrangement that really helps to understand the interest topology. anal is used 23 thousand times and is connected 230 thousands times with almost every other major interest. To visualize a network, you actually need to exclude anal, bdsm and a few others. I also filtered out edges by some criteria, just to be able to look at the rest of the network more conveniently.

This network plot shows 375 nodes and many connections have been removed. It's an interesting starting point but not good for displaying all words and all connections. And, for example, the words 'public' and 'outdoors' are at very different places in the map. One can see that they are related because they have a thick connection drawn in between but i'd rather have them close together. The layout algorithm did what it could.
Note that there is nothing much of the users left in this representation, except the sum of how often each interest has been proclaimed together. Sorting the interests-browser above by the number of edges with your query-interest calculates the relation between one interest and another by how often these terms have been used together, but it's kind of boring. The top interests are spread everywhere.
Large graphs are a heavy topic. There exist neat and well-researched algorithms to extract essential information from graphs, like community detection. But all of them have a terrible run-time for large graphs (e.g. running for days). Sensible pruning or reduction of graphs is the only means i am aware of to run any of the sophisticated graph algorithms in a short amount of time.
Latent representation ←
Instead of comparing interests by their number of connections we can measure similarity in some 'representational space', which might be called latent space, embedding space, latent features or feature vectors. There are many methods to compress complex data into latent features, including many kinds of neural networks. These methods typically create a vector (a list) of numbers of fixed size that can be compared with classic numeric means. A recommendation system can then suggest similar interests by calculating a single number from two feature vectors, e.g., the euclidean distance.
As an example, i added the feature vectors of some text embedding models to the similarity search. They take in a piece of text and output a fixed-sized vector that allows comparing the texts in a numerical way. It was done using the Sentence Transformers library which supports an incalculable collection of models. I picked the following models:
| name in search interface | huggingface page | comment |
|---|---|---|
| granite107M | ibm-granite/granite-embedding-107m-multilingual | It's small, multilingual and quite good |
| zip1M | tabularisai/Zip-1 | It's very small, which makes a difference if you need to embed a trillion texts. Judge it's quality yourself. |
| mdbr-mt22M | MongoDB/mdbr-leaf-mt | A general text embedding model from the MongoDB team |
| mdbr-ir22M | MongoDB/mdbr-leaf-ir | From the same family but fine-tuned for Information Retrieval. Just included both models for comparison. |
The embeddings produced by these models have nothing (or only a microscopic fraction) to do with this dataset. They are trained on huge text corpora to facilitate the search for similar text. For example, the ibm granite model judges love very close to 'romance' and 'romantic', the general MongoDB model ties love to 'relationship' and 'couple'. The MongoDB IR model puts love close to 'innocent', 'beautiful' and 'showing off' (?), while the Zip-1 model more or less fails the love. The embeddings created by these models are a mix of syntactic and semantic features of the input text. E.g., they judge 'winter' and 'winter sports' to be similar but also 'january' or 'snow'.
Here is an example for three different words and how the embeddings of the granite model look like:
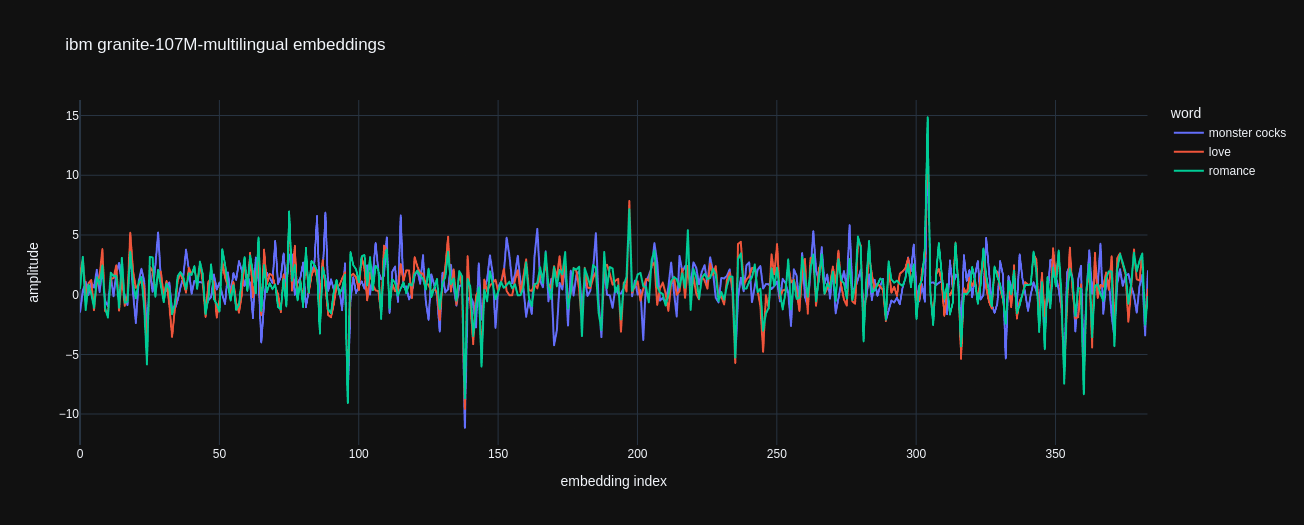
'love' and 'romance' are pretty similar. We don't see much red in the plot because it's mostly behind the green. There is a lot of blue visible, though, because the 'monster cocks' embedding is very different from the other two. Please note that an embedding by itself carries no meaning. We don't know why there is a peak at index 304 and we don't need to care. The embeddings are meaningful only in relation to one another.
If you wonder what the -tsne2 part in the search method dropdown means then jump to the visual representation part. In short, instead of publishing a lot of long embedding vectors i compressed them to 2-dimensional vectors to limit the download bandwidth.
That was a little digression on latent embeddings in general. Now, how do we create numeric vectors that represent this particular porn interests dataset?
Representation learning with PCA ←
We can try to build a model of conglomerated user interest groups from the shared interests. First build a table like this:
| user0 | user1 | user... | user100000 | |
|---|---|---|---|---|
| anal | 1 | 0 | 1 | 0 |
| bdsm | 0 | 0 | 1 | 1 |
| ... | 1 | 1 | 0 | 0 |
Then, for a start, fit a Principal Component Analysis (PCA) to the data. It will squeeze the vector of a 100K+ users into something smaller, say 1000, while preserving a high explainability of the variations in the data. I used the sklearn IncrementalPCA which can be trained in batches which avoids having to put together a potentially gigantic table in memory at once.
I'm actually not sure if it's okay to call PCA a method of representation learning because nowadays, researchers almost always mean some form of neural network training while in comparison, the PCA is an ancient machine learning technique that simply fits a linear model by error-regression. However, it's output is mathematically understandable, it represents the most prominent features in the data and it is not a black-box like most neural networks.
The components of the PCA, after fitting, each represent, in decreasing order of variance explanation, an aspect or trade of a modelled user interest group. That compresses the above table's size to number-of-interests * 1000, which is an acceptable amount of data to process further and still contains (mathematically proven) a high amount of the stuff one is interested in.
To limit the size of the json data in this article, i only included interests that are proclaimed at least 30 times, which are about 3,000. Click here to view them all. This also limits the interest-interest connections to mere 866K.
The interests compressed into numbers by the fitted PCA look like this:
| component0 | component1 | component... | component999 | |
|---|---|---|---|---|
| anal | 113.367 | 15.9827 | -86.7374 | -0.00222 |
| bdsm | 35.8675 | 42.4413 | 25.5585 | -0.00038 |
| ... | 33.5606 | 43.3588 | 23.8518 | -0.00636 |
To conceptually grasp the meaning of this compressed representation, first look at a plot of these numbers for the top-3 interests:
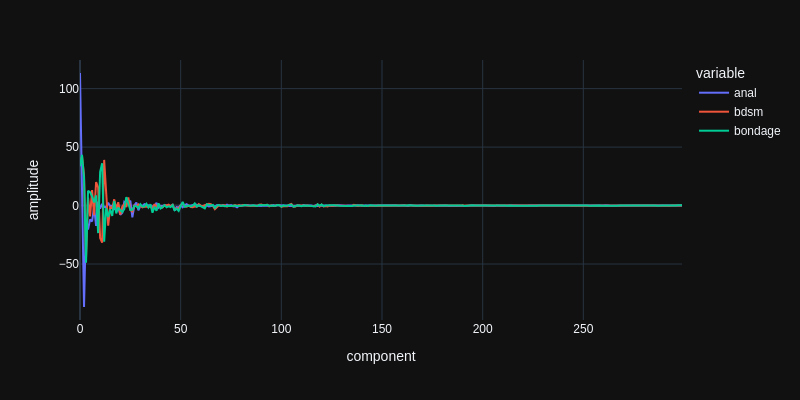
As mentioned above, the components are sorted by variance explanation. The first component explains the most variation in the data. So the mean amplitude of these numbers decreases from left to right. Every further component explains a piece of variation that is not explained by the components before. If we would calculate as many components as there are users, the PCA representation would not be a compression and the user interests could be lossless-ly reproduced from the representation.
Here is a zoomed-in view as bar plot:
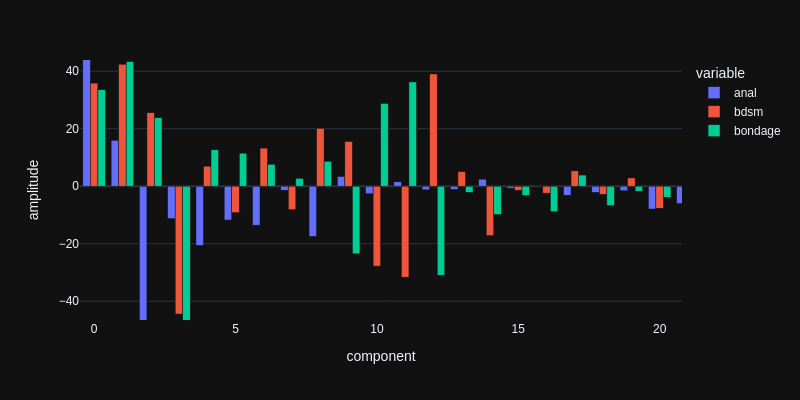
We do not yet know what the components actually represent but we can see that each interest is mapped to a unique mixture of these components. For example, the amplitudes of components 10 and 11 are positive for 'bondage' and negative for 'bdsm' and then it flips at component 12. They are mutually exclusive, although bdsm and bondage are quite related interests. These components seem to explain different streams of interests within the modelled user group. 'anal' just has a small amplitude in these components so it's not about that. Probably both sub-group users like 'anal', like 23 thousand others.
To represent interests and arrive at these numbers, the PCA is learning a number-of-users-sized vectors for each component during training. Those are amplitudes of relations between each component and each user:
| user0 | user1 | user... | user100000 | |
|---|---|---|---|---|
| component0 | 0.00208772 | 0.00158501 | 0.00215929 | 0.00246174 |
| component1 | -0.00518107 | 0.00306462 | -0.00334413 | -0.00128104 |
| component2 | 0.00365257 | 0.0017839 | 0.00269069 | -0.000469027 |
| ... | -0.00235109 | -0.0026599 | -0.000812727 | -0.00101272 |
To calculate the amplitude of, e.g., component 10 from above for the interest 'friends', we create a vector of zeros or ones for each user, putting a one wherever the user has listed 'friends' as interest and then calculate the dot product of this vector and the component vector, which yields a single number: the amplitude of that component for the specified interest.
As long as we have the internal PCA vectors available, we can map back and forth between interests and users. As an example, we can look at which users are weighted strongest (positively and negatively) by component 10.
| user | component 10 weight to user | this user's interests |
|---|---|---|
| user55363 | 0.01943 | anal, big tits, bisexuals, blindfolds, blondes, blowjobs, bondage, brunettes, cock sucking, crossdressers, cum swapping, dildos, fucking, heels and nylons, incest, milfs, pussy licking, redheads, shemales, teen |
| user83340 | 0.01595 | anal sex, bbw, big ass, big tits, blondes, blowjobs, brunettes, deepthroat, ebony, futanari, hentai, lesbian, masturbation, milf, petite, pussyfucking, redheads, shemale, squirting, threesome |
| ... | ||
| user48429 | -0.0144 | amateur, ass, bdsm, black, housewives, lesbian, lezdom, mature, milf, oral, race play, redheads gingers, role play, schoolgirls, small tits, spanking, teens, young |
| user353 | -0.0150 | anal, bareback, bdsm, celebs, creampies, exposure, gangbang, girl girl, groupsex, humiliation, many more, mature, milf, objects, orgies, pee, public, teens, upskirts, voyeur |
The bold words are shared between these 4 positive and negative weighted users, all the other words are not shared. The non-linked words are not in the dataset (used less than 30 times) and have therefore not been seen by the PCA. Looking at the interests, it kind of gives a hint of what this component 10 is about. Or does it? For comparison, here is the same for component 0, the most important one:
| user | component 0 weight to user | this user's interests |
|---|---|---|
| user239 | 0.0121141 | amateur, anal, ass, bdsm, big tits, bondage, brunettes, cuckold, cum, fetish, humiliation, lingerie, milf, panties, pussy, sex, sluts, stockings, swingers, threesome |
| user60045 | 0.0113297 | amateur, anal, ass, bbc, bdsm, bisexual, blowjobs, bondage, captions, chubby, cock, creampie, crossdressing, cuckold, curvy, interracial, latex, pussy, sissy, traps |
| ... | ||
| user82882 | -0.000236861 | bycicling, clothing, cumming, dancing, drinking, driving car, eating, listening to music, painting, reading, riding, singing, sunbathing (beach or solarium), swimming, walking, watching tv, working, writing |
| user18683 | -0.000244663 | blank, dauerwichsen, eng, euter, fett, grabschen, huren, hã¤ngetitten, kein limit, kein taboo, milchtitten, mutter, promis, sacktitten, schwanger, slips, spannen, strumpfhosen, titten, wã¤schewichsen |
I would argue that component 0 has a lot to do with the usage frequency of the interests and, in extension, because of the source material, how 'generically porn' the interest is. user82882 has more facebook-style of interests and, as painful as it is to read user18683's interests, i think they are likely not judged by the PCA as belonging to the 'generic porn interests' group. From what has been put in front of the PCA, it has no idea what the words are. It's only looking at distributions.
Similarly to the weights-per-user we can look at the interests which have the highest or lowest number for a particular component in their representation.
| interest | component 0 amplitude | interest frequency |
|---|---|---|
| anal | 113.382 | 22339 |
| cum | 38.2688 | 9571 |
| mature | 37.2678 | 10514 |
| bdsm | 35.8654 | 10737 |
| bondage | 33.5587 | 10685 |
| ass | 30.7251 | 8133 |
| teens | 30.1846 | 10142 |
| milf | 29.556 | 8386 |
| bbw | 29.4967 | 9000 |
| teen | 29.0985 | 8705 |
| incest | 28.3718 | 9267 |
| amateur | 24.9595 | 7319 |
| pussy | 24.8622 | 6828 |
| sissy | 24.4194 | 7144 |
| oral | 24.057 | 5818 |
| ... | ||
| honesty | -0.934953 | 39 |
| painting | -0.934953 | 38 |
| computer | -0.935473 | 32 |
| pregnant girls | -0.936342 | 33 |
| sun | -0.938043 | 34 |
| fgm | -0.938227 | 31 |
| walking | -0.938477 | 40 |
| magic | -0.938915 | 33 |
| running | -0.939578 | 35 |
| analverkehr | -0.940006 | 30 |
| bleach | -0.940138 | 33 |
| being naked | -0.941903 | 31 |
| working out | -0.942007 | 32 |
| gardening | -0.945972 | 32 |
| singing | -0.952776 | 32 |
Haha, singing and gardening! So, yes, component 0 is highly related to the number of times an interest appears in the dataset. Semantically, analverkehr belongs to the 'typical group of interests` but the PCA is grouping it together with all the other german words. Not because it knows german but from the distributions in the dataset.
The component 10 interests ranking:
| interest | component 10 amplitude | interest frequency |
|---|---|---|
| blondes | 30.2575 | 7389 |
| bondage | 28.7884 | 10685 |
| big tits | 25.748 | 6805 |
| incest | 24.94 | 9267 |
| bbw | 21.9398 | 9000 |
| brunettes | 13.1694 | 3407 |
| redheads | 12.9896 | 4290 |
| teen | 10.176 | 8705 |
| hentai | 8.01342 | 4040 |
| sissy | 6.20872 | 7144 |
| crossdressing | 5.86478 | 4553 |
| lingerie | 5.82677 | 5367 |
| big ass | 5.40358 | 2129 |
| latex | 5.0976 | 3722 |
| ebony | 4.71462 | 3651 |
| ... | ||
| hairy | -3.71873 | 4445 |
| homemade | -3.8613 | 1725 |
| wife | -3.86667 | 2073 |
| gangbang | -3.86836 | 5776 |
| femdom | -4.15352 | 7417 |
| feet | -5.05971 | 6550 |
| milf | -5.70252 | 8386 |
| ass | -6.38355 | 8133 |
| cuckold | -9.01121 | 7399 |
| humiliation | -9.59685 | 7637 |
| voyeur | -9.85645 | 4386 |
| mature | -20.1691 | 10514 |
| amateur | -22.3213 | 7319 |
| bdsm | -27.7799 | 10737 |
| teens | -34.5912 | 10142 |
This component's amplitude is not proportional to the word frequency. Blondes and teens are completely opposite here. As well as bondage and bdsm, as we have seen before. Note that 'teen' and 'teens' are also in the opposite sides of this component. Some deep psychological archetype might divide users that identify themselves as interested in teen from users interested in teens. The terms have not been used together a single time in this dataset.
Now, whatever exact explanation behind each component's meaning might exist, the mixture of a 1000 components should give us a quite diverse map of interest territories.
In the next plot, the interests, sorted by frequency, are put on the x-axis, with the most-used on the left. The y-axis shows the PCA component amplitudes for a couple of components.
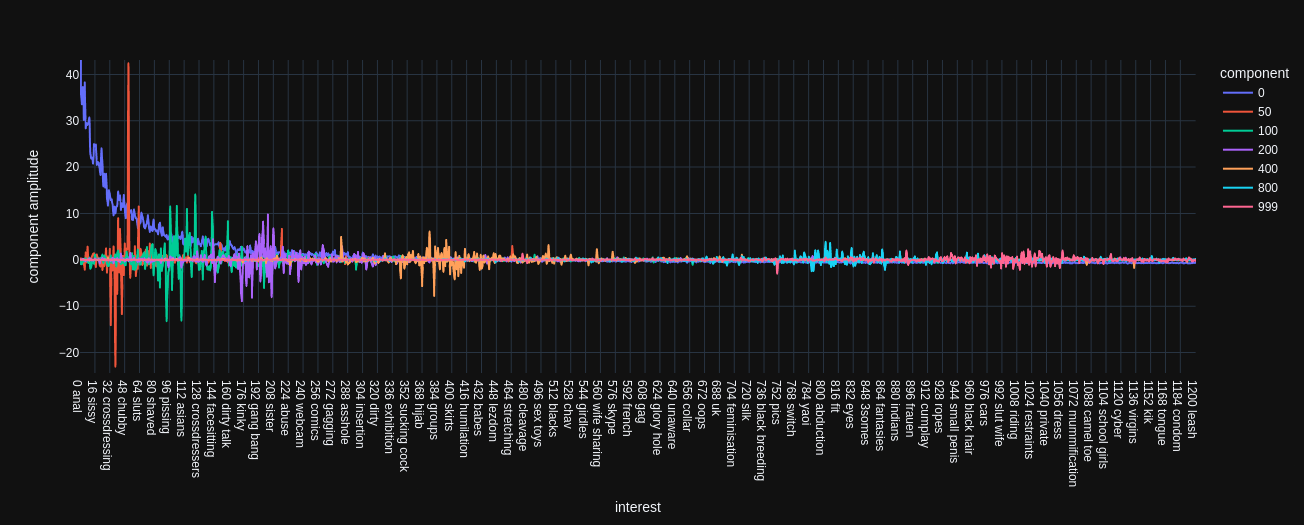
Component 0 (blue) indeed is tied to the interest frequency. I imagine it like this: PCA starts to build user groups and realizes that the most variation in all the data can be explained by how typical or atypical the interests of each user are, in terms of the usage frequency. Then it goes out and tries to find the explanation for all the remaining data variation that is not explained by component 0. Interestingly, in the plot we see that each component's amplitudes are strongest (positive or negative) at around the X-th most frequent interest. Component 50 (red) has the largest amplitudes at around the 50 most frequent interest and this tendency holds for all the other components.
This is not entirely optimal in my opinion. I'd like to calculate interest similarity with less dependence on the actual usage frequency. Eventually, i'm calculating the euclidean distance between those PCA features and a large component amplitude is not similar to a small one. I tried a couple of things to somehow normalize the PCA features but results got much more messy. The similarity search might consider quite unrelated interests as close to each other.
In any case, the PCA is a very powerful and efficient method to get started. Above you can select different PCA component ranges in the method choice-box. For example, pca1000 uses the whole 1000 components to compare the interests, pca100 only uses the first 100 and pca[10:1000] will use all components except the first 10. I included them just for experimentation.
Comparison with Factor Analysis ←
More common in psychology is the Factor Analysis (FA). It tries to explain the variation in the data in terms of a number of unobserved variables that are learned. As initial step, one needs to define the number of components that are taken into account. That's a bit different to PCA, where the first 100 components are the same regardless if we fit a PCA with 100, 200 or a 1000 components. The Factor Analysis gives different results depending on the number of components that are fitted. I tried a few numbers and found that 25 works quite well for this dataset. For example it groups most of the different mother son spellings nicely together, although it does not actually see the words.
Below are two plots like above but for the Factor Analysis with 10 and 25 components each:
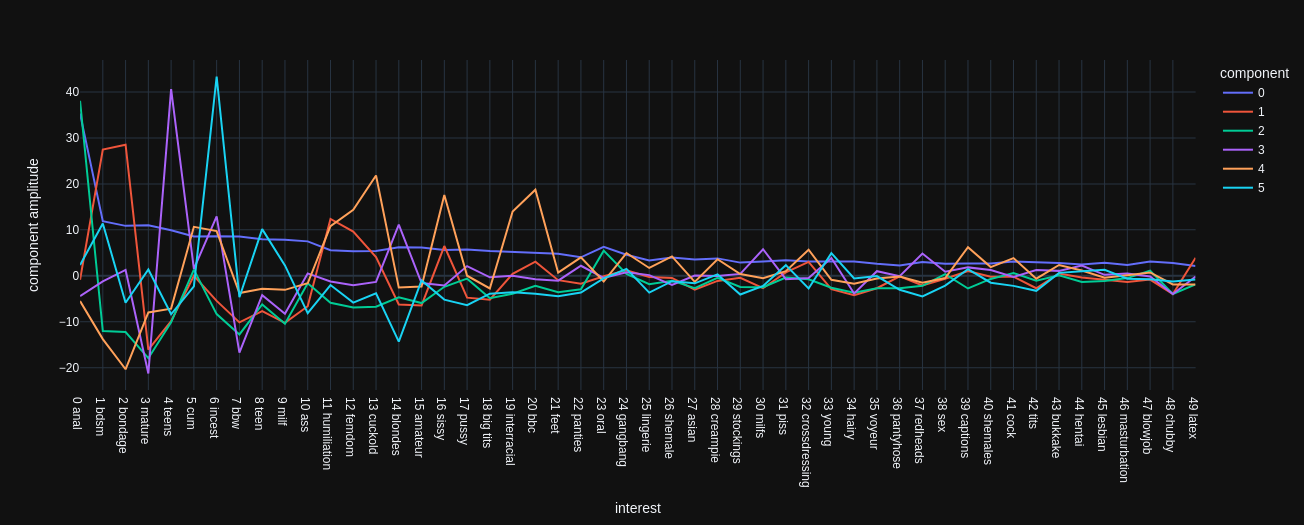
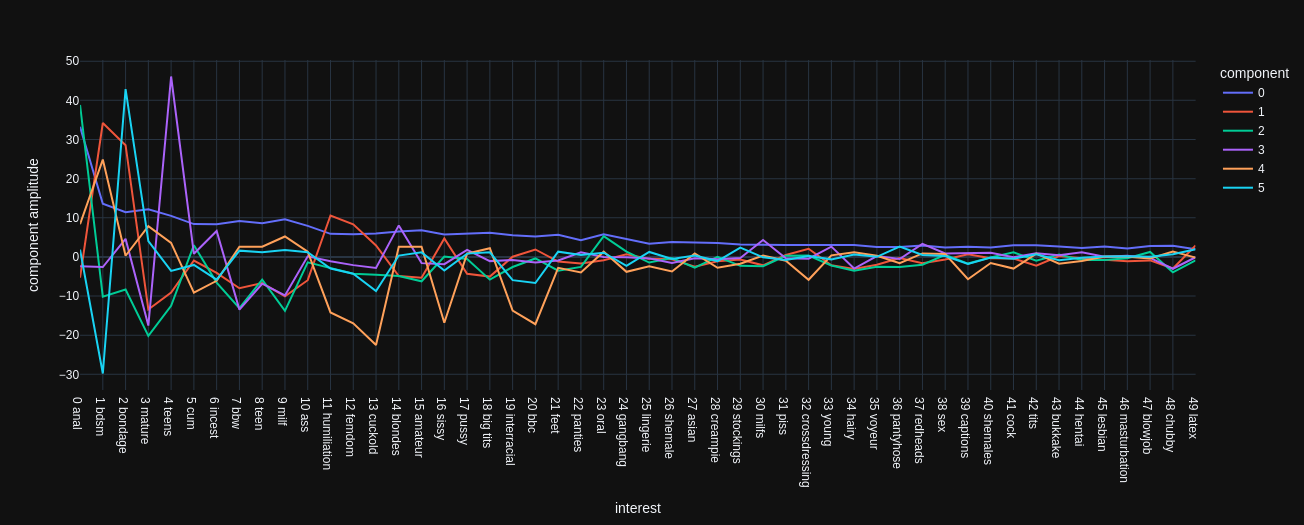
It generally shows the same phenomenon that largest amplitudes are around the X-th most frequent interests. The component 0 is certainly tied to the frequency of the interests as with the PCA. The first 4 components also behave the same for FA10 and FA25 but the following components each describe something different in the data.
There is some open research to determine the correct number of FA factors analytically but i'm not diving into that. I just tried a few numbers and subjectively chose one. You can try the FA with 5, 15 or 25 factors and judge it yourselves.
Finally i merged the (subjectively) best working representations into the magic-mix method. It concatenates, for each interest, the PCA1000 features, the FA25 features and the granite sentence embedding into one vector (1000 + 25 + 384). The sentence embedding is multiplied by 0.3 so it has less influence on the overall interest similarity. However, since the PCA features have a lower amplitude for lesser used interest, as shown above, the sentence similarity has a stronger influence for these interests. I'm telling you because this is an article. A real-world recommendation system usually does not reveal what it is doing behind the curtains.
A little privacy notice.
Below is a comparison for the top-50 interests. It shows the closest interests in terms of edge count (how often used together) and in terms of distance of feature-vectors. Note that we got rid of the 'anal' popping up everywhere without removing it from the graph or similar destructive measures. (The number in brackets is the edge count between top-interest and the closest interest.)
| interest | closest by edge count | closest by pca300 distance | closest by pca1000 distance | closest by fa25 distance |
|---|---|---|---|---|
| anal | oral (3367x) | oral (3367x) | oral (3367x) | fisting (1721x) |
| bdsm | bondage (2982x) | whipping (268x) | flogging (64x) | torture (785x) |
| bondage | bdsm (2982x) | gags (496x) | gags (496x) | latex (1152x) |
| mature | bbw (2676x) | granny (1520x) | granny (1520x) | granny (1520x) |
| teens | anal (2135x) | schoolgirls (209x) | virgins (54x) | young (1039x) |
| cum | anal (3278x) | swallowing (193x) | jizz (91x) | cock (1578x) |
| incest | anal (1952x) | mother (404x) | sister (662x) | family (1128x) |
| bbw | mature (2676x) | ssbbw (914x) | ssbbw (914x) | chubby (1686x) |
| teen | anal (2083x) | girl (155x) | babe (43x) | young (1450x) |
| milf | mature (2676x) | cougar (264x) | gilf (591x) | gilf (591x) |
| ass | anal (2643x) | butt (292x) | butt (292x) | tits (1404x) |
| humiliation | bdsm (1959x) | degradation (866x) | degradation (866x) | degradation (866x) |
| femdom | humiliation (1789x) | forced bi (301x) | ruined orgasm (82x) | chastity (1374x) |
| cuckold | bbc (1687x) | forced bi (185x) | hotwife (730x) | hotwife (730x) |
| blondes | brunettes (1898x) | red heads (230x) | brunettes (1898x) | brunettes (1898x) |
| amateur | anal (1678x) | girlfriend (178x) | homemade (962x) | voyeur (1078x) |
| sissy | anal (1895x) | faggot (268x) | faggot (268x) | crossdressing (1484x) |
| pussy | anal (2067x) | cunt (151x) | closeup (44x) | tits (1329x) |
| big tits | anal (1542x) | big asses (254x) | big areolas (34x) | milfs (659x) |
| interracial | bbc (1936x) | big black cock (174x) | snowbunny (55x) | bbc (1936x) |
| bbc | interracial (1936x) | bwc (367x) | bnwo (461x) | interracial (1936x) |
| feet | anal (1459x) | toes (658x) | toes (658x) | legs (854x) |
| panties | anal (1171x) | bras (316x) | bras (316x) | lingerie (1152x) |
| oral | anal (3367x) | vaginal (94x) | nsa (19x) | sex (519x) |
| gangbang | anal (2048x) | blowbang (242x) | blowbang (242x) | bukkake (1242x) |
| lingerie | stockings (1216x) | bras (161x) | suspenders (47x) | crossdressing (803x) |
| shemale | anal (1700x) | transexual (151x) | ladyboy (450x) | gay (574x) |
| asian | anal (1154x) | thai (198x) | indonesian (72x) | ebony (988x) |
| creampie | anal (1746x) | ao (78x) | insemination (46x) | bukkake (459x) |
| stockings | pantyhose (1521x) | corsets (178x) | suspenders (79x) | pantyhose (1521x) |
| milfs | teens (1255x) | gilfs (293x) | gilfs (293x) | blowjobs (267x) |
| piss | anal (1503x) | shit (221x) | shit (221x) | scat (1173x) |
| crossdressing | sissy (1484x) | transvestite (136x) | femboi (31x) | feminization (636x) |
| young | teen (1450x) | tiny (168x) | little (62x) | taboo (273x) |
| hairy | mature (1426x) | armpits (131x) | hirsute (37x) | ebony (307x) |
| voyeur | amateur (1078x) | spy (201x) | hidden cam (72x) | homemade (285x) |
| pantyhose | stockings (1521x) | tights (670x) | tights (670x) | stockings (1521x) |
| redheads | blondes (1455x) | freckles (189x) | pale skin (44x) | brunettes (973x) |
| sex | anal (1052x) | fuck (109x) | cyber (27x) | oral (519x) |
| captions | incest (854x) | gifs (129x) | babecock (33x) | anime (103x) |
| shemales | anal (1127x) | trannies (160x) | cross dressers (40x) | crossdressers (502x) |
| cock | cum (1578x) | balls (169x) | spunk (28x) | gay (585x) |
| tits | ass (1404x) | cunt (101x) | arse (23x) | boobs (473x) |
| bukkake | anal (1285x) | gokkun (207x) | gokkun (207x) | creampie (459x) |
| hentai | anal (915x) | futa (187x) | pokemon (76x) | anime (659x) |
| lesbian | anal (1112x) | lezdom (90x) | tribbing (31x) | hardcore (210x) |
| masturbation | anal (1015x) | fingering (119x) | ejaculation (28x) | shaved (176x) |
| blowjob | anal (1625x) | rimjob (99x) | titjob (52x) | facial (550x) |
| chubby | bbw (1686x) | plump (136x) | plumper (75x) | ssbbw (153x) |
| latex | bondage (1152x) | rubber (689x) | rubber (689x) | boots (492x) |
Visual representation ←
Okay, so how do we browse this modelled territory of interests except via endless tables of sorted words? The latent vector of any algorithm has a specific size, in our case 1000. That requires 1000-dimensional vision and thinking capability! Fortunately, other 3-dimensional beings have developed nice tools for further compressing an N-dimensional vector to a more comprehensible 2d or 3d version. Compressing our 100K users vector into two dimensions sounds like a very lossy process for sure, but to make far-too-complex data understandable, a plot in two or three dimensions can be very informative. It's not that a 1000-dimensional problem can not be looked at in 2d, it just takes many different angles to do so.
One of the most famous algorithms is tSNE (wiki, python). It's there for the exact purpose of mapping any feature space into two or three dimensions and make it look good. You don't have to think about anything, not even remember what tSNE stands for. Just put your vectors in and get 2d positions out. If there are clusters in the data, tSNE will make them visible. If your data is uniformly distributed, you will see it in the plot. The thing about a point in the map is not if it's east or north, but how far away it is from other points of interest.
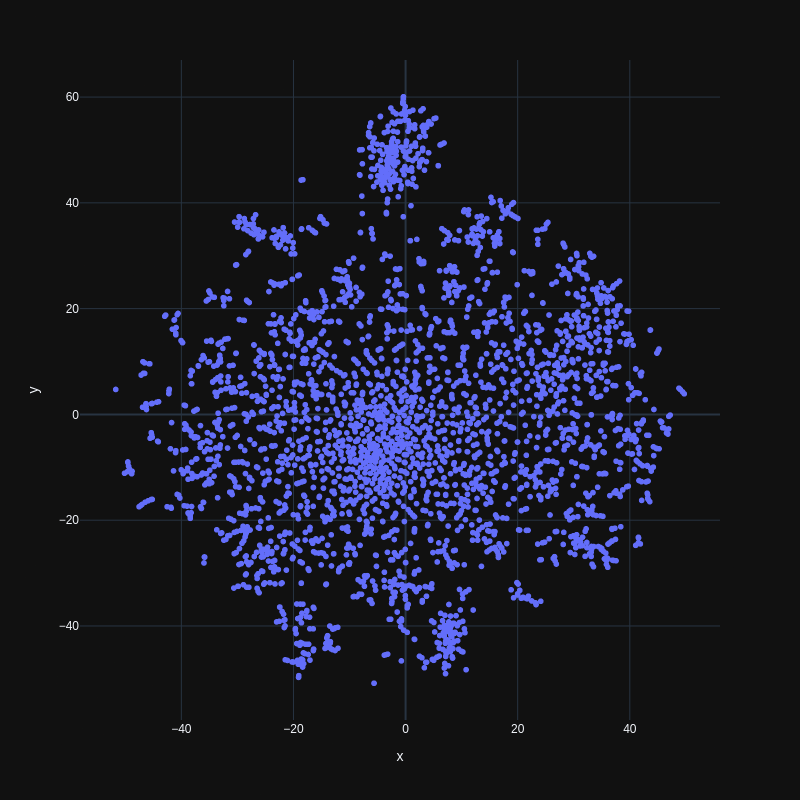
Looks nice, doesn't it? Even without some interactivity like showing the word when hovering a point, one can see some specifics of the whole dataset. It has some homogeneous core, a couple of clusters and a few outliers.
In the Interest Similarity Search above, the similarity is calculated by calculating the euclidean distance of the resulting 2d positions. The 2d map is also displayed in a (pretty ugly) plot. You can zoom in and out (with the mouse-wheel or the zoom buttons) and explore the different interest territories. For the selected interest, all connections to other used-together interests are drawn via lines.
And that's about it. At the moment, i'm quite tired of the whole topic because i spent about two weeks on writing and data-crunching. Hope you enjoy and feel free to drop a comment on github or send me a mail cy5iZXJrZUBuZXR6a29sY2hvc2UuZGU=.