stacked symmetric autoencoder, adding one-layer-at-a-time ←
Trained autoencoder on 3x64x64 images. Encoder and decoder are each 25 layers of 3x3 cnn kernels and a final fully connected layer. code_size=128
In training, every N input steps the number of used layers is increased. First, the autoencoder only uses first encoder and last decoder layer. That way, it's possible to train the whole 25 layers after a time. It's just not good:
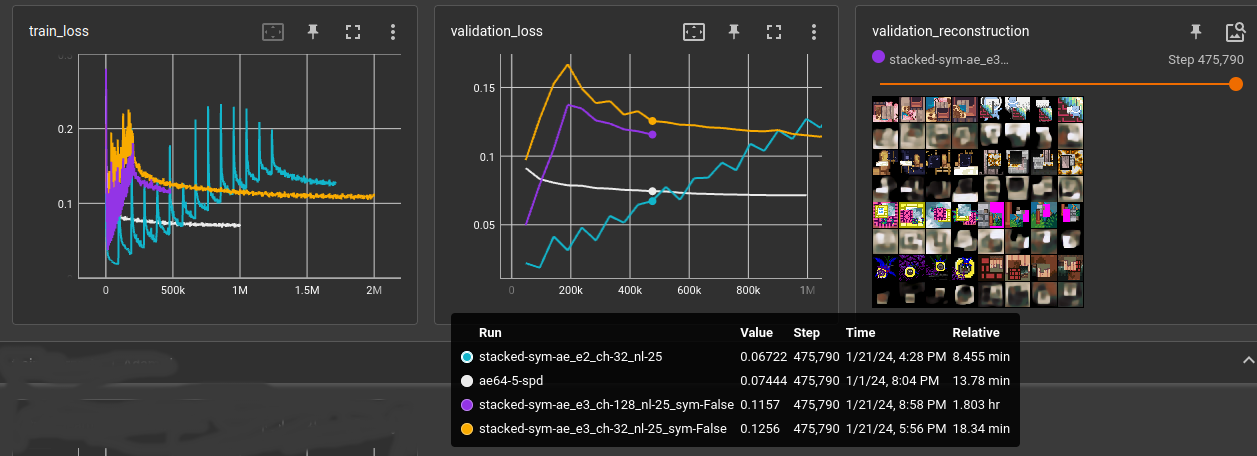
- white: reference baseline cnn (using space-to-depth (or pixel-unshuffle))
- cyan: 32-chan 25 layer cnn, next layer activated every 47,000 steps (1 epoch)
- yellow: 32-chan 25 layer cnn, next layer activated every 8,000 steps
- purple: 128-chan 25 layer cnn, next layer activated every 8,000 steps
Also compared symmetric vs. non-symmetric. Symmetric means the convolutions and fully connected layer use the same weights for encoding and decoding. symmetric is half the number of parameters for the autoencoder and performs only slightly below non-symmetric. The biases are not shared between encoder and decoder.